

Чтобы узнать, как организации общаются в интернете со своей аудиторией, нужно эти организации в интернете сначала найти. Задача эта оказалась нетривиальной: даже если организация зарегистрирована в каком-то реестре, открытой информации о ее сайте как правило нигде нет
Несколько лет назад сооснователь проекта «РосПравосудие» Глеб Суворов предложил проанализировать сайты некоммерческих организаций. В 2021 году руководитель Теплицы Алексей Сидоренко продолжил эту идею, тогда так и не реализованную, и развил ее в проект по изучению и мониторингу состояния различных коммуникаций некоммерческих организаций и общественных инициатив. Так появилась Лаборатория исследований гражданского общества. Начать изучение коммуникаций НКО мы решили с того, как они общаются с аудиторией через сайты.
Первой задачей Лаборатории мы поставили собрать базу НКО с действующими сайтами. За основу мы взяли реестр Минюста России. Впрочем, реестром это назвать сложно: портал, на котором можно просмотреть сведения об организациях, не имеет ни API, ни дампов данных, ни какого-либо описания того, что в нем можно найти. В итоге в качестве отправной точки мы использовали проект Инфокультуры «Открытые НКО». Во-первых, в нем уже содержались разные сведения, собранные в реестре Министерства юстиции: название, дата регистрации, ОГРН, регион, адрес, правовая форма и статус (зарегистрирована либо исключена). Однако этих сведений очень мало, и Инфокультура обогатила их данными из ЕГРЮЛ, из финансовых отчетов, размещенных на сайте Минюста, а также из реестров субсидий, президентских грантов и госзакупок. Для нашей первой цели — выяснить, у каких НКО есть сайты, казалось достаточно сведений из ЕГРЮЛ. Однако обработав все дампы, мы нашли сайты только у 5,2 тыс организаций (меньше 1% от всех найденных «действующих»). Как будто бы очень мало! Где же еще мы можем найти списки сайтов НКО?
Мы стали придумывать разные способы поиска сайтов НКО. Вбивать их названия в Яндексе? Но названия многих организаций очень похожи. Например, одних только организаций с названием «Ромашка» нашлось в реестре Минюста 14 штук:

Обсудив минусы и трудозатратность такого способа, мы не стали даже пытаться его применить. Что если использовать более уникальное обозначение, например, ОГРН? В идеальном мире организации указывают свою юридические данные у себя на сайтах, однако мы живем не в идеальном мире. Первый же вопрос, который мы задали себе: даже если на сайте организации указано ее верное юридическое название или ОГРН, насколько сайт адаптирован к поисковым движкам? Насколько хорошо он индексирован? Будет ли он на первых строчках поисковой выдачи? Кстати, эти вопросы привели нас в итоге к идее включить показатели поисковой оптимизации в расчеты коммуникативного потенциала сайта. Мы решили не пытаться найти сайты организаций по их названиям и регистрационным номерам и обратиться к другим источникам.
Теплица много лет помогает разным некоммерческим организациям создавать и настраивать сайты, и мы предположили, что у коллег будет информация о том, какой организации какая страничка принадлежит в Интернете. Из предоставленных коллегами данных мы сопоставили несколько сотен НКО с их сайтами. Также мы воспользовались порталом «Если быть точным» и добавили в нашу базу несколько десятков НКО с сайтами.
Самым значительным источником данных для нас в итоге оказалась коммерческая база «СПАРК-Интерфакс». В ней содержится обогащенная из многих источников и верифицированная информация обо всех юридических лицах России. В ней мы нашли еще несколько тысяч сайтов. Чтобы отобрать сайты из всего ЕГРЮЛ, мы использовали параметры общероссийского классификатора организационно-правовых форм (ОКОПФ).
Дисклеймер
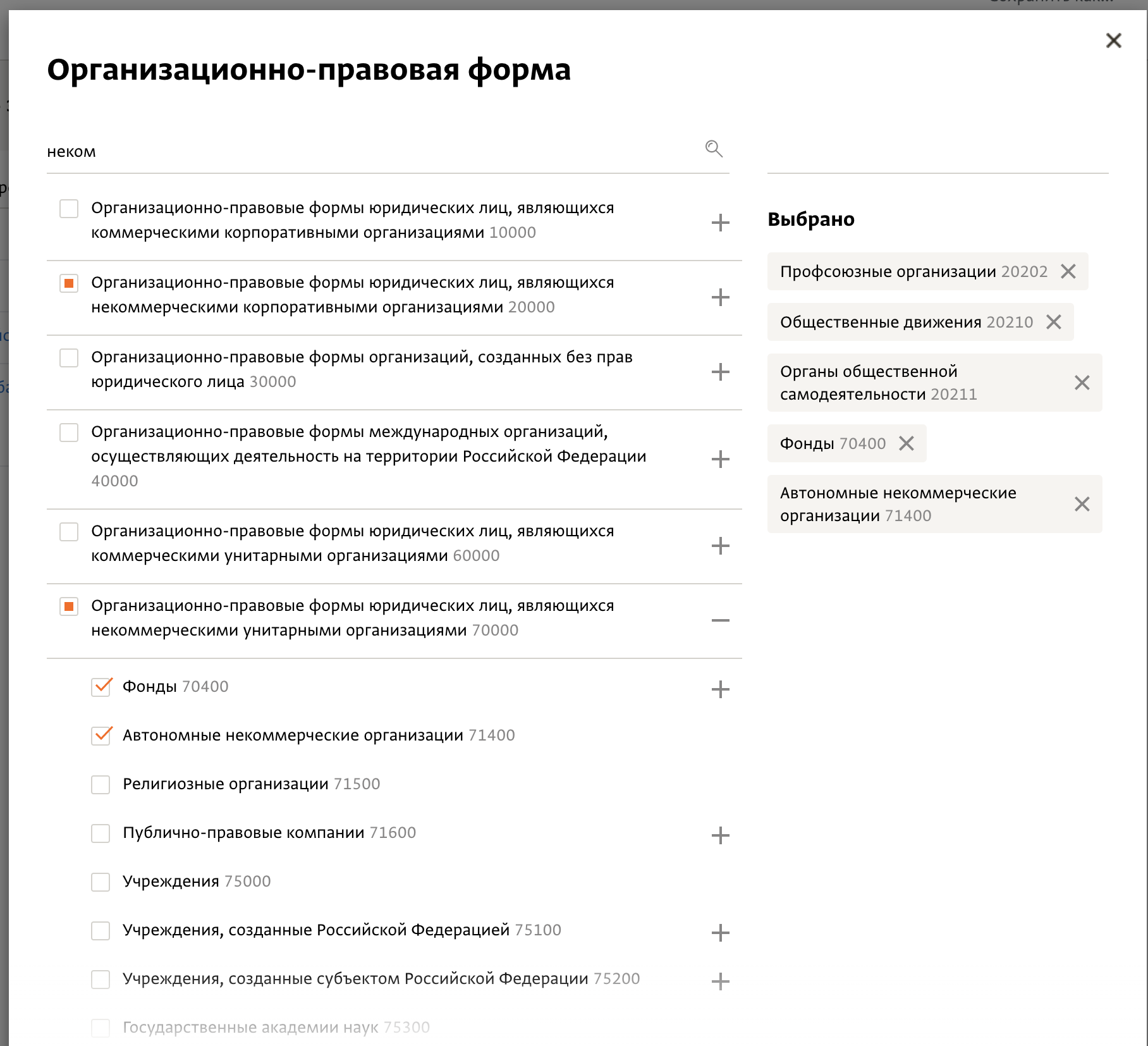
Мы приняли решение, что работаем только с некоторыми видами некоммерческих организаций — такими, которые, на наш взгляд, наиболее склонны к активной внешней коммуникации, аудитория которых максимально широка и присутствие которых онлайн может быть более важным, нежели для организаций с другой формой. К примеру, адвокатская палата тоже является некоммерческой организацией, однако она едва ли нацелена на внешнюю коммуникацию, активный поиск новой аудитории, работу с большим количеством стейкхолдеров, а членство в ней ограничено узкой группой людей определенной специализации. Потребительский кооператив — это узкая группа людей, объединенная скорее имуществом или общим делом. Но не стали рассматривать сайты политических партий и религиозных организаций, так как сочли их деятельность слишком специфической и политически ангажированной.
Как мы объединили данные и сделали «Грядку»
Так как все исходные данные имели разные наборы фич — где-то была детализация вплоть до имени руководителя и номера телефона, где-то имелись сведения о соцсетях, где-то иностранные названия, а где-то не было ничего из этого,
Так как все исходные данные имели разные наборы фич — где-то была детализация вплоть до имени руководителя и номера телефона, где-то имелись сведения о соцсетях, где-то иностранные названия, а где-то не было ничего из этого — перед нами стояла задача объединить все собранные наборы в единый датасет. Мы назвали новую объединенную базу «Грядка» и оставили на ней все полезные культуры, то есть не избавлялись от фич, если в одном наборе они есть, а в другом нет. Таким образом, мы получили датасет в котором было 39 столбцов и более 22 тысяч строк.

Уникальным идентификатором организации для нас выступил регистрационный номер (ОГРН). При этом мы понимали, что из связки «ОГРН — адрес сайта» мы изначально были уверены только в том, что отбираем ОГРН действующей организации. А вот живы ли сайты, нам еще предстояло узнать.
Мы решили проверить, до какого числа делегировано доменное имя. Для этого мы использовали пакет python-whois. С его помощью можно получить такие данные:
{'domain_name': 'SABF.RU',
'registrar': 'RU-CENTER-RU',
'creation_date': datetime.datetime(2020, 2, 3, 9, 49, 14),
'expiration_date': datetime.datetime(2023, 2, 3, 9, 49, 14),
'name_servers': ['ns1.jino.ru.',
'ns2.jino.ru.',
'ns3.jino.ru.',
'ns4.jino.ru.'],
'status': 'REGISTERED, DELEGATED, VERIFIED',
'emails': None,
'org': 'Charitable foundation for helping people with Angelman syndrome "Angel Syndrome"'}
Однако начав работать с «прополотой» таким способом Грядкой, мы выяснили, что иногда, даже если домен делегирован и актуален, в действительности сайт может не работать, например, у него не оплачен хостинг. Тогда мы провели еще проверку ответа от сервера — действующими считали сайты, сервер которых при обращении давал код «200». Впоследствии, когда мы начали проводить тесты и собирать отдельные характеристики сайтов веб-скрейпингом, мы также заметили, что изредка на сайтах с действующим хостингом и делегированным доменом может не быть никакого контента — открывается просто пустая HTML-страница и даже круче: хотя сервер выдает ответ «200», на самой странице размещена заглушка, извещающая об ошибке «404». Тогда мы написали еще один скрипт для «прополки», чтобы исключить подобные случаи.
В итоге в нашей выборке стало гораздо меньше сайтов — около 10 тысяч. Зато теперь мы точно были уверены, что все они на момент проведения исследования (зима 2021-2022 года) работают.